
How to understand and optimize your site’s search signals
Optimizing a website for your target audience and search engines requires gathering the right data and understanding its significance. It can be a challenge for large websites but there is an enterprise level solution: DeepCrawl. With DeepCrawl, sites can be crawled in a similar way to Search engine bots. More importantly, sites can be seen and understood from a search engine’s point of view. Lastly, little effort is required to optimize search signals and make a site visible in Google’s organic search. Here are 40 small steps to get there!
1. Find Duplicate Content

Duplicate content is an issue for search engines and users alike. Users don’t appreciate repeated content that adds no additional value, while search engines can be confused by duplicate content, and fail to rank the original source as intended. You can help your trust perception on both fronts by finding duplicate titles, descriptions, body content, and URLs with DeepCrawl. Click through the post-audit content tab in your crawl report to see all web pages with doppelganger-style content.
DeepCrawl scans your project domains for duplicate content as part of its default practices during web and universal crawls. Adjust sensitivity to duplicated content in the report settings tab of your project’s main dashboard before you launch your next crawl. Easy!
2. Identify Duplicate Pages
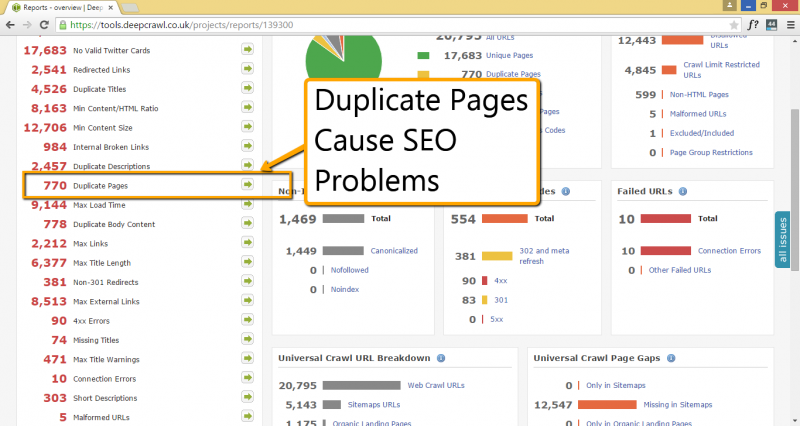
Duplication is a very common issue, and one that can be the decisive factor when it comes to authority. Using DeepCrawl, you can view a full list of duplicate pages to get an accurate picture of the problem. This feature helps you consolidate your pages so your site funnels visitors to the right information, giving your domain a better chance at conversion and reduces pages competing for the same search result rankings.
How To Do It:
- Click “Add Project” from your main dashboard.
- Pick the “web crawl” type to tell DeepCrawl to scan only your website at all its levels.
- Review your site’s duplicate pages from the “issues” tab located in the left panel of your main reporting dashboard once the crawl finishes.
3. Optimize Meta Descriptions
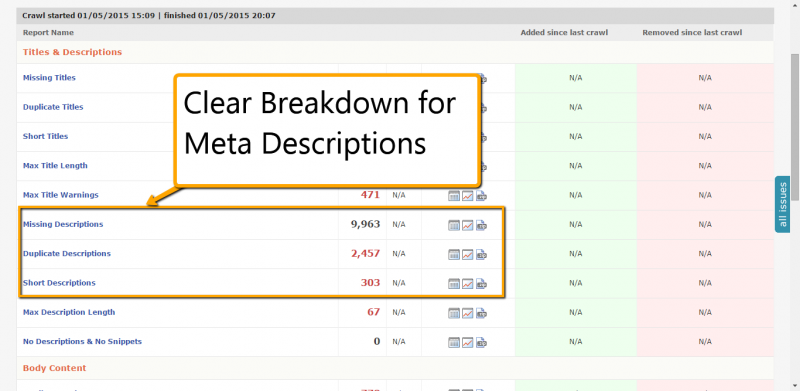
Meta descriptions can greatly influence click-through rates on your site, leading to more traffic and conversions. Duplicate and inconsistent descriptions can negatively impact user experience, which is why you want to prioritize fixes in this area. Through the content report tab, DeepCrawl gives you an accurate count of duplicate, missing and short meta descriptions. This lets you identify problem areas, and turn them into positive search signals that work for, rather than against, your site.
4. Optimize Image Tags

Google Image Search is a huge opportunity to claim SERP real estate. Missing image alt tags are organic traffic opportunities lost. Using DeepCrawl’s custom extraction tool, you and your team can set crawls to target images and audit their corresponding alt tags. You can access this feature through the Advanced Settings tab in your project’s main dashboard.
How To Do It:
- Create custom extraction rules using Regular Expressions syntax.
- Hint: Try “/(<img(?!.*?alt=([‘”]).*?2)[^>]*)(>)/” to catch images that have alt tag errors or don’t have alt tags altogether.
- Paste your code into “Extraction Regex” from the Advanced Settings tab in your projects dashboard.
- Check your reports from your projects dashboard when the crawl completes. DeepCrawl gives two reports when using this setting: URLs that followed at least one rule from your entered syntax and URLs that returned no rule matches.
5. Crawl Your Site like Googlebot

Crawl your website just like search engine bots do. Getting a comprehensive report of every URL on your website is a mandatory component of regular maintenance. With DeepCrawl, you can dig into your site without slowing its performance. Because the crawler is cloud-based, there’s minimal impact on your website while the crawl is in progress. Choose “universal crawl” to also crawl your most important conversion pages and XML sitemaps with a single click.
6. Discover Potentially Non-indexable Pages

Improve user experience on your site by identifying non-indexable pages that are either wrongly canonicalized and potentially missed opportunities or may be wasting precious crawl budget. In DeepCrawl, from the content tab of your completed crawl, you can review every no-indexed page on your entire website based on the type of no-indexing (e.g. nofollowed, canonicalization and noindex).
7. Compare Previous Crawls

As part of its native feature set, DeepCrawl compares page level, indexation, http status and non-index changes from your previous crawls to create historical data for your organisation. This view helps you to identify areas that need immediate attention, including server response errors and page indexation issues, as well as parts that show steady improvement.
In addition, get a visual display of how your site’s web properties are improving from crawl to crawl with this project-level view. You can get info for up to 20 concurrent projects right from the monitoring tab in your main project dashboard. DeepCrawl caches your site data permanently, meaning you can compare how your website progressed from crawl to crawl.

How To Do It:
- Download crawl data from a finished report in .xls or .pdf format.
- Add client logo or business information to the report.
- Serve data to your client that’s formatted to look as though it came directly from your shop.
8. Run Multiple Crawls at Once

Resource-draining site audits are a thing of the past. Thanks to cloud-based servers, you can run up to 20 active crawls spanning millions of URLs at once and still use your computer to do whatever other tasks you need it for… And best of all, all the data is backed up in the cloud.
9. Avoid Panda, Manage Thin Content

Search engines have entire algorithm updates focused on identifying thin content pages. Track down thin content on your website by using DeepCrawl’s content audit tab. Clicking the “min content size” section gives you every URL with pages that have content below three kilobytes. This filter gives your team a list of URLs which serves as a starting point for further investigation. Excluding lean content pages from being indexed or enriching their content can help the improve the website both from a user experience and a search engine optimization point of view.
How To Do It:
- From the report settings tab, adjust the minimum content size by kilobytes.
- If you do not change the setting, DeepCrawl will scan your URLs for the default min content size of three kilobytes.
- Fine tune as necessary.
10. Crawl Massive Sites

You may have to crawl a website that spans over 1 million URLs. The good news is that DeepCrawl can run audits for up to 3 million URLs per crawl, giving you the powerful tool your site size demands.
How To Do It:
- From the crawl settings tab in your projects dashboard, adjust the crawl limit to suit your target domain’s total URLs.
- Crawl up to 1 million URLs using prefabricated settings in DeepCrawl’s dropdown “crawl limits” menu.
- For a custom crawl, select “custom” from the dropdown menu and adjust max URLs and crawl depth to suit your reporting needs.
- Crawl Limit: 3 million URLs per crawl.
11. Test Domain Migration

Newly migrated websites can experience server-side issues and unexpected URL complications that can lead to page display errors and downtime. Check status codes post-migration from your project’s reporting dashboard. There you can see the total number of non-200 status codes, including 5xx and 4xx errors, DeepCrawl detected during the platform’s most recent audit. Use this information to see if URLs that your team redirected are working as intended.
12. Track Migration Changes

Website migration is often a painstaking effort involving multiple development teams, technical SEOs, and decision makers. Use DeepCrawl to compare your site’s post-migration structure to a previous crawl dating back before the move. You can choose to compare the newest crawl to any previously-run data set to see if teams missed their assignments or if old problems managed to make their way into the site’s new web iteration.
13. Find 404 Errors

Correcting 404 errors helps search crawlers navigate your pages with less difficulty and reduces the chance that searchers might land on content that serves an “oops!” message and not products. Find 404s using DeepCrawl from your report’s main audit dashboard. One click gives you a full list of a 4xx errors on site at the time of audit, including their page title, URL, source code and the page the link to the 404 was found on.
14. Check Redirects

Check the status of temporary and permanent redirects on site by clicking through the “non-200 status codes” section on your project dashboard. Download 301 and 302 redirects into .CSV files for easy sorting, or share a project link with team members to start the revision process.
15. Monitor Trends Between Crawls
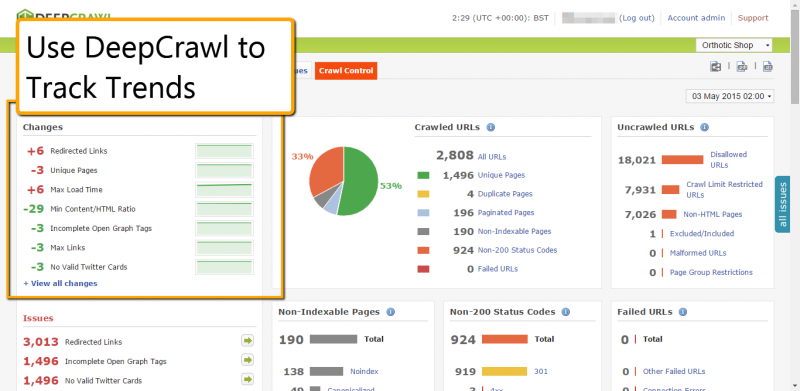
Tracking changes between crawls gives you powerful data to gauge site trends, emerging issues, and potential opportunities. You can manually set DeepCrawl to compare a new crawl to its previous audit of the same site from the “crawls” tab in the project management section. Once finished, the new crawl shows your improved stats in green and potential trouble areas in red. The overview includes link data, HTML ratio and max load times among others.
16. Check Pagination

Pagination is crucial for large websites with many items, (such as e-commerce websites),helping to make sure the right pages display for relevant categories. Find paginated URLs in the “crawled URLs” section of your audit’s overview dashboard. From this section, your team can check rel=next and rel=prev tags for accuracy while vetting individual URLs to make sure they’re the intended targets.
17. Find Failed URLs

When a URL fails on your website, DeepCrawl’s spider can’t reach it to render the page, which means users and search engines probably can’t get there either. Investigate connection errors and other issues that can cause failed URLs through your project’s main reports dashboard. Finding the source of these issues can help you improve your site’s user experience by improving server response times and reducing time-out connection errors. You can find more information about Connection errors in DeepCrawl’s guide.
18. Crawl Sitemaps for Errors
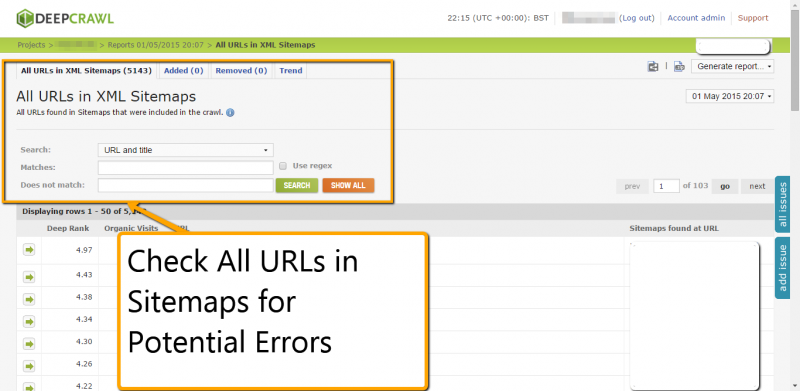
Problems in your XML sitemap can lead to delays in search engines identifying and indexing your important pages. If you’re dealing with a large domain with a million URLs, finding that one bad URL can be a challenge. Put DeepCrawl to work with the platform’s universal crawl feature. From this tab in your project reporting dashboard, review URLs missing from your sitemap, all pages included in your sitemaps, broken sitemaps, and sitemap URLs that redirect.
19. Improve Your Crawls with Google Analytics Data

Validating your Google Analytics account when you create a new project gives DeepCrawl the ability to overlay organic traffic and total visits on your individual URLs and paths. Seeing this data helps with prioritizing changes coming out of your site audit. For example, if you notice low organic traffic to product pages that have thin or duplicate content, that may serve as a signal to speed up revamping those URLs.
How To Do It:
- Select a universal crawl when setting up your new project.
- Click save and click over to the “analytics settings” that now appears in the top menu.
- Click “add new analytics account” located in the top left of the dashboard.
- Enter your Google Analytics name and password to sync your data permissions within the DeepCrawl platform.
- Hit save and DeepCrawl will pull analytics data for all domains you have permission to view on current and future crawls.
20. Verify Social Tags

To increase share rates from your blog posts on Facebook and Twitter and thereby enhance your community outreach activities, avoid any errors in your social tag markup. View Twitter Cards and Open Graph titles, images, and URLs to see what needs fixing.
21. Test Individual URLs

Granular reporting over thousands of landing pages is difficult to grasp, but DeepCrawl makes the process digestible with an elegant statistical breakdown. View unique pages by clicking the link of the same name (unique pages) in your dashboard overview. From here, you can see a detailed breakdown of page health, including external links, word count, HTML size, and nofollow tag use.
22. Verify Canonical Tags

Incorrect canonical tags lead crawlers to ignore canonicals altogether, leaving your site in danger of duplication and search engines having trouble correctly identifying your content. View canonicalized pages in your DeepCrawl audit by clicking through from the “non-indexable pages” section of the project’s dashboard. The platform gives you the canonical’s location, HTML, title tag, and URLs to help with verification.
23. Clean Up Page Headers

Cluttered page headers can impair the click through rate if users’ expectations are not being managed well. CTRs can vary by wide margins, which makes it difficult to chart the most effective path to conversion. When you run a universal crawl, make sure to integrate your Google Analytics account. This will help you gain a deeper insight, by combining crawl data with powerful analytics data including bounce rate, time on page, and load times.
24. Make Landing Pages Awesome
 Page-level elements, including H1 tags, compelling content, and proper pagination, are essential parts of your site’s marketing funnel that helps turn visitors into leads. Use DeepCrawl’s metrics to help improve engagement and conversion. Find content that is missing key parts through the “unique pages” tab, including H1s, H2s, sitemap inclusion, and social markup, to help them engage visitors faster, deliver your site’s message in a clearer fashion, and increase chances for conversions and exceeding user expectations.
Page-level elements, including H1 tags, compelling content, and proper pagination, are essential parts of your site’s marketing funnel that helps turn visitors into leads. Use DeepCrawl’s metrics to help improve engagement and conversion. Find content that is missing key parts through the “unique pages” tab, including H1s, H2s, sitemap inclusion, and social markup, to help them engage visitors faster, deliver your site’s message in a clearer fashion, and increase chances for conversions and exceeding user expectations.
25. Prioritize Site Issues

Knowing what to address first in the aftermath of a sizable audit can be a challenging task for any site owner. Using the project management tab, you can assign tasks emerging from the audit to your team members and give each task a priority rating. This system helps you track actions from your site audit by priority and assigned team member through the “all issues” tab, accessible from any page. You can view the age of each task, leave notes for team members, and mark projects as fixed, all from the same screen in the DeepCrawl projects platform. For assignments with several moving parts, including 404 cleanups and page title correction, projects count down remaining URLs until they reach zero.

26. Check for Thin Content

Clean, efficient code leads to fast loading sites – a big advantage in search engines and for users. Search engines tend to avoid serving pages that have thin content and extensive HTML in organic listings. Investigate pages that don’t meet DeepCrawl’s min content/HTML ratio by clicking through the tab of the same name in your project’s main reporting dashboard. View pages by title and URL, exporting the list as a .CSV or shared link.
27. Crawl as Googlebot or Your Own User Agent

If your site auditor can’t crawl your pages as Googlebot, then you have no prayer of seeing your domain through the search giant’s eyes. DeepCrawl can mimic spiders from other search engines, social networks, and browsers, including Firefox, Bing, and Facebook. Select your user agent in the advanced settings tab after you choose the website you want to audit.
28. Discover Disallowed URLs

Never crawled (or disallowed) URLs may contain broken links, corrupted files, and poorly coded HTML that can impact site performance. View disallowed pages from the overview section of your site’s crawl report. From this section, you can see all disallowed pages and their corresponding URLs and then get the picture on which URLs may not be crawled by search engines.
29. Validate Page Indexation

DeepCrawl gives you the versatility to get high-level and granular views of your indexed and non-indexed pages across your entire domain. Check if search engines can see your site’s most important pages through this indexation tab, which sits in the main navigation of your reporting dashboard. Investigate no-indexed pages to make sure you’re only blocking search engines from URLs when it’s absolutely necessary.
30. Sniff Out Troublesome Body Content
Troublesome content diminishes user confidence and causes them to generate negative behavioral signals that are recognized by search engines. Review your page-level body content after a web crawl by checking out missing H1 tags, spotting pages with threadbare word count, and digging into duplication. DeepCrawl gives you a scalpel’s precision in pinpointing the problems right down to individual landing pages, which enables you to direct your team precisely to the source of the problem.
How To Do It:
- From the report settings tab in your project dashboard, set your “duplicate precision” setting between 1.0 (most stringent) and 5.0 (least stringent).
- The default setting for duplicate precision is 2.0, if you decide to run your crawl as normal. If you do not change your settings, the crawl will run at this level of content scrutiny.
- Run your web crawl.
- Review results for duplicate body content, missing tags, and poor optimization as shown above.
31. Set Max Content Size

Pages that have a high word count might serve user intent and drive conversion, but they can also cause user confusion. Use DeepCrawl’s report settings tab to change max content size to reflect your ideal word count. After your crawl finishes, head to the “max content size” section from the audit dashboard to find pages that exceed your established limit.
How To Do It:
- In the report settings tab of your project dashboard, adjust maximum content size by KB (kilobytes).
- Hint: one kilobyte equals about 512 words.
- Check content that exceeded your KB limit from the finished crawl report.
32. Fixing Broken Links

Having too many broken links to external resources on your website can lead to a bad user experience, as well as give the impression your website is out of date. Use the validation tab from your web crawl dashboard to find all external links identified by DeepCrawl’s spider. Target followed links, sorting by http status, to see URLs that no longer return 200 “OK” statuses. These are your broken links. Go fix them.
33. Schedule Crawls
 Use DeepCrawl’s report scheduling feature to auto-run future crawls, including their frequency, start date, and even time of day. This feature can also be used to avoid sensitive and busy server times or have monthly reported emailed directly to you or your team.
Use DeepCrawl’s report scheduling feature to auto-run future crawls, including their frequency, start date, and even time of day. This feature can also be used to avoid sensitive and busy server times or have monthly reported emailed directly to you or your team.
How To Do It:
- From the projects dashboard, click on the website you’d like to set reporting schedules.
- Click the scheduling tab.
- Set the frequency of your automated crawl, start date, and the hour you’d like the crawl to site.
- Check back at the appointed time for your completed crawl.
34. Give Your Dev Site a Checkup

Your development or staging site needs a checkup just like your production website. Limit your crawl to your development URL and use the universal or web crawl settings to dig into status codes and crawl depth, locating failed URLs, non-indexable pages and non-200 codes by level.
How To Do It:
- Run a universal crawl to capture all URLs in your target domain, including sitemaps.
- When the crawl finishes, check your non-200 status codes and web crawl depth from the reports dashboard.
- Examine the crawl depth chart to see where errors in your development site’s architecture occur most often.
35. Control Crawl Speed

At crawl speeds of up to twenty URLs per second, DeepCrawl boasts one of most nimble audit spiders available for online marketers working with enterprise level domains. Sometimes, however, speed isn’t what is most important; accuracy is what matters. Alter crawl speeds by how many URLs are crawled per second or switching from dynamic IP addresses to static, stealth crawl, or location-based IP from the advanced settings tab during initial audit setup.
36. Custom Extraction

Add custom rules to your website audit with DeepCrawl’s Custom Extraction tool. You can tell the crawler to perform a wide array of tasks, including paying more attention to social tags, finding URLs that match a certain criteria, verifying AppIndexing deeplinks, or targeting an analytics tracking code to validate product information across category pages. For more information about Custom Extraction syntax and coding, check out this tutorial published by the DeepCrawl team.
How To Do It:
- Enter your Regular Expressions syntax into the Extraction Regex box from the advanced settings tab on your DeepCrawl projects dashboard.
- Click the box underneath the Extraction Regex box if you’d like DeepCrawl to exclude HTML tags from your crawl results.
- View your results by checking the Custom Extraction tab in your project crawl dashboard.
37. Restrict Crawls

Restrict crawls for any site using DeepCrawl’s max URL settings or the list crawl feature. The max setting places a cap on the total number of pages crawled, while the list feature restricts access to a set of URLs you upload before the audit launches.
How to Do It (Include URLs):
- Go to the “Include Only URLs” section in the Advanced Settings tab when setting up your new project’s crawl.
- Add the URL paths you want to include in the box provided on single lines. DeepCrawl includes all URLs with the paths you enter in them when you begin your crawl.
- Ex: /practice-areas//category/
How to Do It (Exclude URLs):
- Navigate to the “Excluded URLs” section in the advanced settings tab of your project setup dashboard.
- Add URL paths you want to exclude from your crawl by writing them on single lines in the box provided using the method as outlined above.
- Important Note: Exclude rules override include rules you set for your crawl
- Bonus Exclude: Stop DeepCrawl from crawling script-centric URLs by adding “*.php” and “*.cgi” into the exclude URLs field.
38. Check Implementation of Structured Data

Access Google’s own Structured Data Testing Tool to validate Schema.org markup by adding a line or two of code to your audit through DeepCrawl’s Custom Extraction. This tool helps you see how your rich snippets may appear in search results, where errors in your markup prevent it from being displayed, and whether or not Google interprets your code, including rel=publisher and product reviews, correctly.
How To Do It:
- Choose the “list crawl” option during your project setup.
- Enter a list of URLs you want to validate into the box provided. If you have over 2,000 URLs in your list, you’ll need to upload them as a .txt file.
- Add the Custom Extraction code found here to get DeepCrawl to recognize Schema markup tags and add the particular line of code you want for your crawl: ratings, reviews, person, breadcrumbs, etc.
- Run Crawl. You can find the info DeepCrawl gleaned on your site’s structured markup by checking the Extraction tab from the reporting dashboard.
39. Verify HREFLANG Tags

If your website is available in multiple languages, you need to validate the site’s HREFLANG tags. You can test HREFLANG tags through the validation tab in your universal crawl dashboard.
If you have HREFLANG tags in your sitemaps, be sure to use the universal crawl as this includes crawling your XML sitemaps.
How To Do It:
- Run a universal crawl on your targeted website from the projects dashboard.
- Once the crawl finishes, head to the reports section under “validation.”
- From there you can view pages with HREFLANG tags and pages without them.
- View URLs flagged as inconsistent and alternative URLs for all country variations on the domain.
40. Share Read-Only Reports

This is one of my favorite options: Sharing reports with C-levels and other decision makers without giving them access to other sensitive projects is easily doable with DeepCrawl. Generate a “read-only” URL to give them a high-level view of the site crawl as a whole or to kick out a link that focuses on a granular section, including content, indexation and validation.
Last but not least
This top 40 listing is by no means complete. In fact, there are many more possibilities to utilize DeepCrawl for enhancing site performance and the tool undergoes constant improvements. This list is a starting point to understanding your website as Google does and making improvements for users and search engines alike. DeepCrawl is a very powerful tool and conclusions drawn using the data it provides must be based on experience and expertise. If applied to its full effect DeepCrawl can bring an online business to the next level and significantly contribute to user expectations management, brand building and most importantly driving conversions.
What are your favourite DeepCrawl features? Your opinion matters, share it in the comments section below.






